





«Баги» мозга: упрощения и уловки восприятия мира
Сергей Абдульманов, специалист по когнитивистике и играм написал для geekimes отличный текст о том, как наш мозг оптимизирует свои ресурсы, упрощая для нас понимание сложного и многослойного мира. И что с этим можно делать.
Мозг чайки и оранжевое пятно
Представьте, что вы проектируете птенца чайки. ТЗ такое: у него довольно плохое зрение, маленький мозг, но ему нужно как можно больше есть, а то сдохнет. Еду ему приносит мама-чайка. Основная задача — распознать маму-чайку и получить у неё еды. Во входной поток зрения поступает, скажем, 320х200 px, и дальше 10 сантиметров от глаза он не умеет фокусироваться. Природа решила так — надо разметить клюв чайки ярким оранжевым округлым пятном.
Вот таким:

В ходе реверс-инжиниринга чайки в 1950-х Нико Тинберген провёл 2431 опыт с 503 птенцами (часть его коллега Рита Вейдманн высидела сама). Выяснилось, что птенец реагирует и не только на клюв, но и на картонный прямоугольник с круглым оранжевым пятном. И пытается получить у него еду как у обычной чайки. Звучит логично, особенно в условиях нехватки вычислительных ресурсов птенца, правда? «Появляется сверху», «длинный» — это важно. Но самая высокая ценность сигнала «оранжевый на белом» — и она по мере эволюции завышается.
Под самый конец внезапно нашёлся ультранормальный сигнал. Если птенцу показать прямоугольник с тремя оранжевыми полосами, он распознает его куда быстрее, точнее, и среагирует в разы активнее. То есть сильнее распознаётся другой образ, которого нет в природе.
Если вы думаете, что мы с вами, как представители homo sapiens, не «забагованы», то ошибаетесь. У нас, людей, есть примерно такой же пример переобучения, хорошо известный анимешникам.
Модель зрения человека
Исторически предполагалось, что мы смотрим на что-то и делаем следующее (всё куда сложнее и запутаннее, я сильно упрощаю, поэтому заранее прошу прощения за грубую модель):
- Получаем входной массив данных в виде чего-то вроде BMP-файла.
- Обрабатываем эту картинку на зрительных рецепторах, чтобы сконвертировать в импульсы для мозга. То есть переводим этот BMP во внутренний формат мозга.
- Несём подальше от сенсоров в центр обработки, где придаём полученной картинке смысл, то есть конвертируем в следующий формат — скорее всего, околословарный, потому что по нему потом задействуются ассоциации.
- Понимаем смысл изображения и показываем его сознательной части разума.
На деле же оказалось, что процесс куда веселее. Нет смысла «грузить» всю картинку в первичную обработку, когда можно сильно оптимизировать этот процесс. Поэтому мы делаем следующее:
- Получаем первичный контур данных, грубо говоря, несколько процентов от всего сенсорного ввода.
- Сразу гоним его в обработку с вопросом, что грузить дальше. Обработка (за пределами сенсора, в мозгу) связывается со словарём форм-ассоциаций и говорит, что мы, скорее всего видим — то есть отдаёт на управление сенсором гипотезы.
- Управление сенсором начинает «грузить» то, что может подтвердить или опровергнуть наиболее вероятные гипотезы — то есть мы последовательно забираем ещё несколько процентов данных, отдаём их сразу в обработку и получаем результат, как и на что смотреть дальше.
- Когда гипотеза остаётся только одна — имея неполный файл, мы уже знаем, что на нём изображено. В этот момент происходит ещё одна конвертация уже в сознательный формат.
Чтобы было понятно, о какой скорости речь — В. Н. Панферов (под руководством А.А. Бодалева) определял порог узнавания лица на фотографии — это 0,03-0,04 секунды. Волосы и верх головы обрабатывались в этих пределах, а вот подбородок и нос распознавались уже где-то в три раза медленнее — на 0,1 с.
Повторюсь, модель крайне примерна, но показывает важнейшее отличие: мы не обрабатываем, что увидел глаз, а управляем глазом так, чтобы он искал знакомые нам шаблоны. Чтобы далеко не ходить — вот пример реализации этой уязвимости:
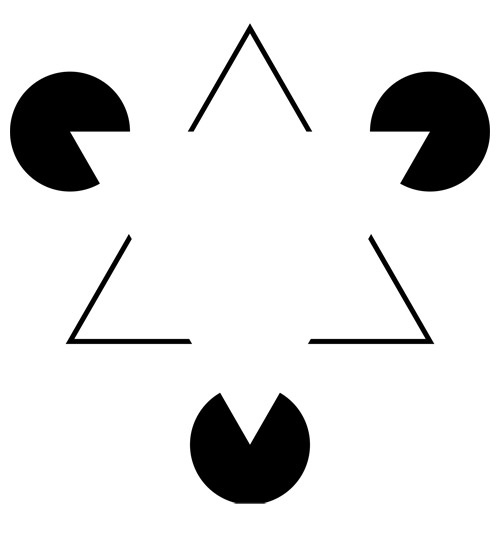
На картинке можно увидеть белый треугольник. Более того, некоторые даже могут «увидеть» его границы — там, где их на самом деле нет.
Но, что для нас гораздо важнее в плане переобучения наших нейросетей распознавания образов, мы распознаём многие объекты по нескольким опорным точкам. Например, очень простые рисунки позволяют быстрее распознавать объекты, чем содержащая куда больше информации фотография. Потому что в упрощённом рисунке уже выделены те черты, которые нейросеть художника посчитала значимыми, и наша нейросеть также приняла их за: опорные точки.
Распознавание человека человеком: упрощение восприятия
А теперь вернёмся к упомянутым анимешникам. Если задуматься, то любое комиксово-рисованное изображение девушки не может быть привлекательнее живой девушки. Ну, пусть у нас будет идеализированная девушка в аниме и ещё одна с идеальной фигурой-макияжем — на фото. Большая часть аниме ориентирована на ультранормальный сигнал — мы распознаём опорные части образа и останавливаемся.
Вот, смотрите:

*Залито на sketchport.com пользователем Envynity.
Мы распознаём этот набор визуальных сигналов как, возможно, вполне симпатичную деву. Однако если у реальной дамы будут глаза такого же размера, прыщ вместо носа, странный рот, полупрозрачные волосы и вообще примерно похожая анатомия, плюс она заложит непослушный локон за глаз… Ну, некоторые схватятся за осиновый кол.
Картинка иллюстрирует, как выделяются главные для нейросети объекты и гасятся второстепенные. Да-да, это тоже наш ультранормальный сигнал — быстрый для распознавания, но в реальном мире означающий ложноположительную сработку. Знакомьтесь: мы только что посмотрели на аналогию картонки с тремя полосками, которую показывали птенцам чайки.
Аналогично грудь нереального размера у некоторых античных статуй — не ошибка физилогии, а художественная гипербола, подчёркивающая нужное качество.
Вот ещё пример для тех, кто не увидел симпатичную девушку на картинке выше:

Schyns P.G., Oliva A. J. Cognition — при загрузке деталей первое лицо злое, второе — нет. Мне достаточно снять очки, а вам — возможно надо будет отойти подальше от монитора или уменьшить картинку. При достаточном уровне размытия наша нейросеть опирается вообще на другие точки, и выражения лиц меняются местами.
Баги человеческого восприятия: проекция по неполным данным
Второй баг этого же класса (но куда более высокоуровневый) — это проекция по неполным данным. Серия экспериментов Алана Миллера и уже упомянутого Бодалева доказала, что мы строим полный образ человека, на который опираемся до получения новых данных, на основе крайне обрывочных кусков информации. Например, мы обучены, что все волосатые очкарики — ботаны (пока не получим в глаз от одного такого), все китайцы низкие (пока не увидим их представителей, присланных на парад к нам на прошлое 9 мая — не меньше 210 сантиметров каждый) и так далее.
Обратимся к более простым реализациям этой функции: например, стоит вспомнить, что крысы пугаются любых пушистых предметов размера кошки, потому что чем яснее будет распознана кошка, тем это важнее для выживания. Крысы выживают именно за счёт снижения ложноотрицательных статусов.
У нас с вами есть такая милая особенность — генерализация страха. Например, если целенаправленно научить ребёнка бояться плюшевую крысу, то он будет пугаться вообще половины плюшевых игрушек, поскольку его нейросеть забрала не только основной классифицирующий признак, но и кучу вспомогательных — и решила, что по сравнению с опасностью не распознать сигнал — допустимая жертва.
Генерализация работает и у животных. Более того, она отлично сочетается именно с нейрообучением. Если крысе давать бегать в лабиринте в ветке с кругом, квадратом и прямоугольником с пропорциями сторон 2:1, но кормить только после того, как она побежит к прямоугольнику — крыса научится отличать прямоугольник с пары попыток и будет бегать только к нему. Заменим лабиринт — вместо круга теперь второй квадрат. Снова бежит к прямоугольнику с первой попытки. Теперь меняем лабиринт — оставляем квадрат и прямоугольники с пропорциями сторон 2:1 и 3:1.
Логика предполагает, что крыса бежит к уже знакомому ей 2:1. Но нет, она, оказывается, выучила, что чем прямоугольнее — тем лучше. И бежит в 3:1, полагая, что там еды больше. Потому что на этот прямоугольник её нейросеть «где еда» даёт более сильный сигнал срабатывания.
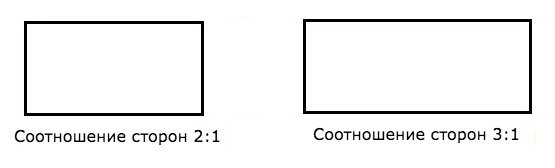
Результат эксперимента: несмотря на то, что еду крысам давали за прямоугольник с соотношением сторон 2:1, при добавлении прямоугольника 3:1 — они предпочитали его. Мозг крыс считал это как «чем вытянутее, тем вероятнее еда».
Ещё одну уязвимость человеческого мозга нашёл Мортен Крингельбах в Оксфорде, работая с «Крайслером». Доведённый до ума опыт выглядит так: показываем женщинам фотографии чего-то милого, например, младенцев. Фиксируем, что происходит в мозге. Теперь показываем женщинам фотографии новых вариантов экстерьера автомобиля, и ищем наибольшее соответствие предыдущему шаблону. Получаем самый милый из возможных автомобилей.
Сравните Matiz и Smart. Да-да, мы узнаём «детёнышей» и включаем родительскую реакцию при определённых пропорциях лица. Например, у щенка, зайчонка, котёнка, птенца и младенца будут явно укороченные и менее выступающие носы, большие глаза. Не верите примеру про машину — посмотрите на детёныша капибары, родившегося недавно в Московском зоопарке. Вот новость о нём — там серия фото:


Если не знать заранее, что это младенец, можно принять его за взрослую особь. Потому что нос длинный, и выбивается из наших шаблонов родительской реакции. И наша нейросеть может сориентироваться, что это детёныш, только по габаритному размеру в сравнении с другой особью – ну или заголовку новости.
Природные триггеры
Ну и напоследок: гуппи распознают друг друга по оттенкам цвета. Самцы имеют большой жёлтый маркер во всё туловище. Этот жёлтый маркер ищут самки, которым неймётся размножаться. Так вот, биологи решили проверить, как самки добились нужной точности. В результате опытов они покрасили самца в ярко-синий. И — та-дам! — выяснилось, что они действительно используют метрику «чем более синий, тем лучше».
А колюшки-самцы (не путать с корюшкой) ловятся вообще на красную нитку — для них всё шевелящееся красное является мгновенным триггером на запуск инстинкта атаки. Потому что самец приманивает самок движениями туда-сюда и красной окраской брюха. А нитка ведёт себя даже более «самцово», чем настоящая рыба. Надо укусить эту наглую штуку, правда?
У галок есть триггер «напасть, если тащат что-то чёрное болтающееся» — это защита гнездовья от тех, кто ворует птенцов. Не подходите к ним с носками в руках. Те же чайки выкидывают красные яйца из гнезда — инстинкт избавления от раненых птенцов.
Если интересны подробности советую исследования 50-х вроде «Восприятие человека человеком» (А. А. Бодалев) и опыты, описанные Н. Тинбергеном в «Осы, птицы, люди».
Источник: geektimes.ru
Читайте также на Зожнике:
7 веществ, продлевающих здоровье и молодость мозга
Фитнес для мозга: тренировки с нейропротекторным эффектом
Новые способы познать тайные возможности мозга
Мозг на пенсии: что происходит с мозгом при старении
Как душевные переживания отражаются на телесном благополучии